Not-forking is a technical tool for software development. Not-forking assists with reproducibility.
Here are some simple ways of explaining what Not-forking can do:
- Not-forking lets you integrate non-diffable codebases, a bit like patch/sed/diff/cp/mv rolled into one.
- Not-forking is a machine-readable file format and tool. It answers the question: What is the minimum difference between multiple source trees, and how can this difference be applied as versions change over time?
- Not-forking avoids duplicating source code. When one project is within another project, and the projects are external to each other, there is often pressure to fork the inner project. Not-forking avoids that.
- Not-forking helps address the problem of reproducibility. By giving much better control over the input source trees, it is more likely that the output binaries are the same each time.
But here is the big win: Not-forking avoids project-level forking by largely automating change management in ways that version control systems such as Fossil, Git, or GitHub cannot.
The full documentation goes into much more detail than this overview.
Not-forking was a pre-requisite to for LumoSQL to exist, but unlike LumoSQL is fully production-ready.
I designed and tested Not-forking, and Claudio Calvelli did most of the coding as can be seen in the commit logs…
This following diagram shows the simplest case:
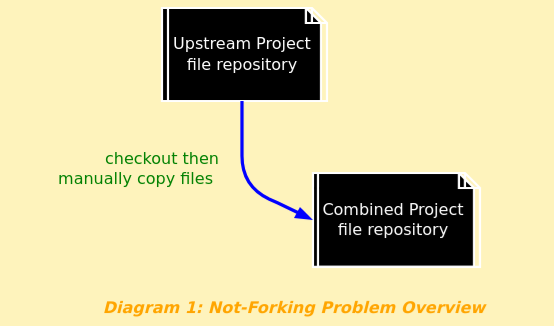
Some questions immediately arise:
- Should you import Upstream into your source code management system?
- If Upstream makes modifications, how can you pull those modifications into Combined Project safely?
- If Combined Project has changed files in Upstream, how can you merge them safely?
Not-forking also addresses more complicated scenarios:
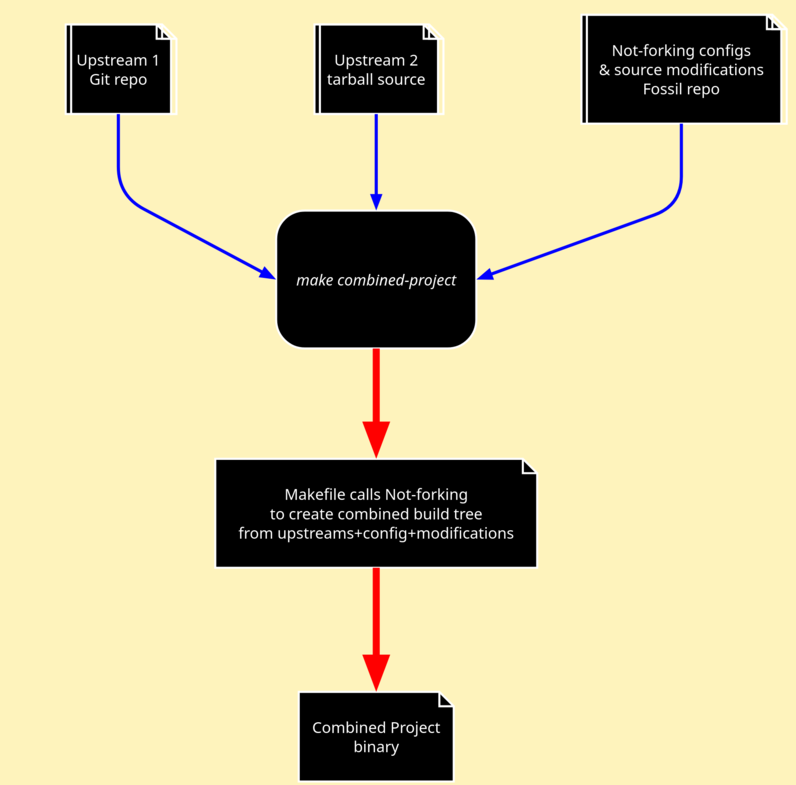
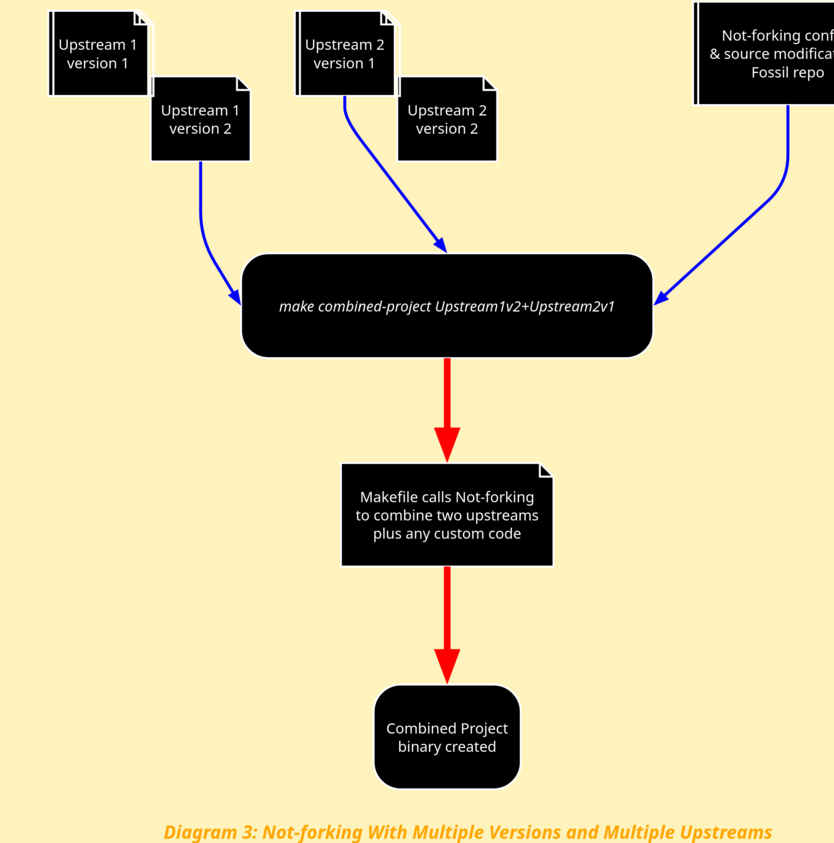
And even more complex cases:
Why Not Just Use Git/Fossil/Other VCS?
Git rebase cannot solve the Not-forking problem space. Neither can Git submodules. Nor Fossil’s merge, nor the quilt approach to combining patches.
A VCS cannot address the Not-forking class of problems because the decisions required are typically made by humans doing a port or reimplementation where multiple upstreams need to be combined. A patch stream can’t describe what needs to be done, so automating this requires a tangle of fragile one-off code. Not-forking makes it possible to write a build system without these code tangles.
Examples of the sorts of actions Not-forking can take:
- check for new versions of all upstreams, doing comparisons of the human-readable release numbers/letters rather than repo checkins or tags, where human-readable version numbers vary widely in their construction
- replace foo.c with bar.c in all cases (perhaps because we want to replace a library that has an identical API with a safer implementation
- apply this patch to main.c of Upstream 0, but only in the case where we are also pulling in upstream1.c, but not if we are also using upstream2.c
- apply these non-patch changes to Upstream 0 main.c in the style of sed rather than patch, making it possible to merge trees that a VCS says are unmergable
- build with upstream1.c version 2, and upstream3.c version 3, both of which are ported to upstream 0’s main.c version 5
- track changes in all upstreams, which may use arbitrary release mechanisms (Git, tarball, Fossil, other)
- cache all versions of all upstreams, so that a build system can step through a large matrix of versions of code quickly, perhaps for test/benchmark